

First when you hear the term “Erasure Coding”, confused? , Let’s clarify this. what is “Erasure Coding” , Erasure Coding is a general term that refers to *any* scheme of encoding and partitioning data into fragments in a way that allows you to recover the original data even if some fragments are missing. Any such scheme is refer to as an “erasure code” , this clarified from VMware Blog .
RAID-5 and RAID-6 are introduced in vSAN to reduce the overhead when configuring virtual machines to tolerate failures. This feature is also termed “erasure coding”. RAID 5 or RAID 6 erasure coding is a policy attribute that you can apply to virtual machine components. They are available only for all-flash vSAN Cluster, and you cannot use it on hybrid configuration.
RAID-5/RAID-6 on vSAN
To configure RAID-5 or RAID-6 on VSAN has specific requirement on the number of hosts in vSAN Cluster. For RAID-5, a minimum of 4 hosts and for RAID-6 a minimum of 6. Data blocks are placing across the storage on each host along with a parity. Here there is no dedicated disk allocated or storing the parity, it uses distributed parity. RAID-5 and RAID-6 are fully supported with the new deduplication and compression mechanisms in vSAN .
RAID-5 – 3+1 configuration, 3 data fragments and 1 parity fragment per stripe.
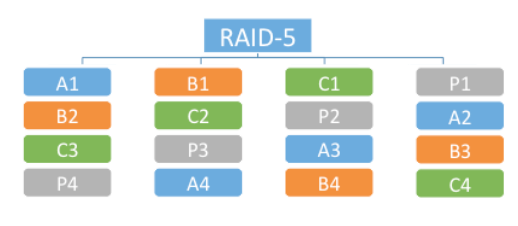
RAID-6 – 4+2 configuration, 4 data fragments, 1 parity and 1 additional syndrome per stripe.
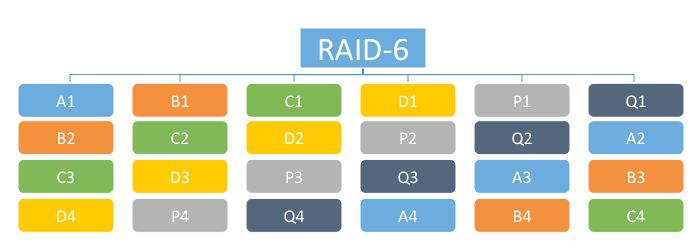
To Learn More on RAID Levels , Check STANDARD RAID LEVELS
You can use RAID 5 or RAID 6 erasure coding to protect against data loss and increase storage efficiency. Erasure coding can provide the same level of data protection as mirroring (RAID 1), while using less storage capacity.
RAID 5 or RAID 6 erasure coding enables vSAN to tolerate the failure of up to two capacity devices in the datastore. You can configure RAID 5 on all-flash clusters with four or more fault domains. You can configure RAID 5 or RAID 6 on all-flash clusters with six or more fault domains.
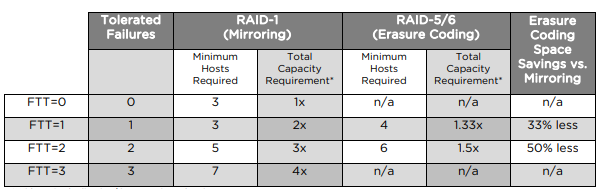
RAID 5 or RAID 6 erasure coding requires less additional capacity to protect your data than RAID 1 mirroring. For example, a VM protected by a Primary level of failures to tolerate value of 1 with RAID 1 requires twice the virtual disk size, but with RAID 5 it requires 1.33 times the virtual disk size. The following table shows a general comparison between RAID 1 and RAID 5 or RAID 6.
| RAID Configuration | Primary level of Failures to Tolerate | Data Size | Capacity Required |
| RAID 1 (mirroring) | 1 | 100 GB | 200 GB |
| RAID 5 or RAID 6 (erasure coding) with four fault domains | 1 | 100 GB | 133 GB |
| RAID 1 (mirroring) | 2 | 100 GB | 300 GB |
| RAID 5 or RAID 6 (erasure coding) with six fault domains | 2 | 100 GB | 150 GB |
RAID-5/6 (Erasure Coding) is configured as a storage policy rule and can be applied to individual virtual disks or an entire virtual machine. Note that the failure tolerance method in the rule set must be set to RAID5/6 (Erasure Coding).
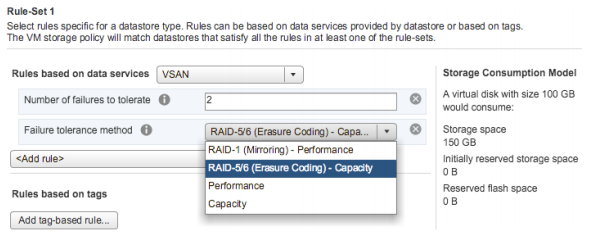
Additionally In a vSAN stretched cluster, the Failure tolerance method of RAID-5/6 (Erasure Coding) – Capacity applies only to the Secondary level of failures to tolerate .
RAID-1 (Mirroring) vs RAID-5/6 (Erasure Coding).
RAID-1 (Mirroring) in Virtual SAN employs a 2n+1 host or fault domain algorithm, where n is the number of failures to tolerate. RAID-5/6 (Erasure Coding) in Virtual SAN employs a 3+1 or 4+2 host or fault domain requirement, depending on 1 or 2 failures to tolerate respectively. RAID-5/6 (Erasure Coding) does not support 3 failures to tolerate.
Erasure coding will provide capacity savings over mirroring, but erasure coding requires additional overhead. As I mentioned above erasure coding is only supported in all-flash Virtual SAN configuration and effects to latency and IOPS are negligible due to the inherent performance of flash devices.
Overhead on Write & Rebuild Operations
Overhead on Erasure coding in vSAN is not similar to RAID 5/6 in traditional disk arrays. When anew data block is
written to vSAN, it is sliced up, and distributed to each of the components along with additional parity information. Writing the data in distributed manner along with the parity will consume more computing resource and write latency also increase since whole objects will be distributed across all hosts on the vSAN Cluster .
All the data blocks need to be verified and rewritten with each new write , also it is necessary to have a uniform distribution of data and parity for failure toleration and rebuild process . Writes essentially are a sequence of read and modify, along with recalculation and rewrite of parity. This write overhead occurs during normal operation, and is also present during rebuild operations. As a result, erasure coding rebuild operations will take longer, and require more resources to complete than mirroring.
RAID-5 & Raid 6 conversion to/from RAID-1
To convert from a mirroring failure tolerance method, first you have to check vSAN cluster meets the minimum host or fault domain requirement. Online conversion process adds additional overhead of existing components when you apply the policy. Always it is recommended do a test to convert virtual machines or their objects before performing this on production , it will help you to understand the impact of process and accordingly you can plan for production .
Because RAID-5/6 (Erasure Coding) offers guaranteed capacity savings over RAID-1 (Mirroring), any workload is going to see a reduced data footprint. It is importing to consider the impact of erasure coding versus mirroring in particular to performance, and whether the space savings is worth the potential impact to performance. Also you can refer below VMware recommendations .
Recommendations













