Elastic DRS allows scaling your VMware Cloud on AWS cluster according to demand by adding or removing hosts automatically based on specific policies. This feature further extends the availability and resiliency of the SDDC cluster and removes the infrastructure operations burden from the customer.
Elastic DRS uses an algorithm to maintain an optimal number of provisioned hosts to keep cluster utilization high while maintaining desired CPU, memory, and storage performance. Elastic DRS monitors the current demand on your SDDC and applies an algorithm to make recommendations to either scale in or scale out the cluster. A decision engine responds to a scale-out recommendation by provisioning a new host into the cluster. It responds to a scale-in recommendation by removing the least-utilized host from the cluster.
Elastic DRS is not supported for the following types of SDDCS:
Special considerations apply to two-host SDDCs. Only the Default Storage Scale-Out policy is available for two-host SDDCs. EDRS cannot scale in an SDDC to fewer than three hosts. Therefore, when a two-host SDDC is scaled out to three hosts, it cannot be scaled back to two hosts. When the Elastic DRS algorithm initiates a scale-out, all Organization users receive a notification in the VMC Console and through email.
The Elastic DRS algorithm monitors resource utilization in a cluster over time. After allowing for spikes and randomness in the utilization, it makes a recommendation to scale out or scale in a cluster and generates an alert. This alert is processed immediately by provisioning a new host or removing a host from the cluster.
The algorithm runs every 5 minutes and uses the following parameters:
A scale-out recommendation is generated when any CPU, memory, or storage utilization remains consistently above thresholds. For example, if storage utilization goes above the high threshold but memory and CPU utilization remain below their respective thresholds, a scale-out recommendation is generated. A vCenter Server event is posted to indicate the start, completion, or failure of scaling out on the cluster.
A scale-in recommendation is generated when CPU, memory, and storage utilization all remain consistently below thresholds. The scale-in recommendation is not acted upon if the number of hosts in the cluster is at the minimum specified value. A vCenter Server event is posted to indicate the start, completion, or failure of the scaling in operation on the cluster.
Note:
Whenever you reduce cluster size, storage latency increases due to process overhead introduced by host removal. The duration of this overhead varies with the amount of data involved. It can take as little as an hour, though an extreme case could require more than 24 hours. While cluster-size reduction (scale-in) is underway, workload VMs supported by the affected clusters can experience significant increases in storage latency.
A safety check is included in the algorithm to avoid processing frequently generated events and to provide some time to the cluster to cool off with changes due to last event processed. The following time intervals between events are enforced:
The following operations might interact with Elastic DRS recommendations:
Normally, you would not need to manually add or remove hosts from a cluster with Elastic DRS enabled. You can still perform these operations, but an Elastic DRS recommendation might revert them at some point.
If a user-initiated add or remove host operation is in progress, the current recommendation by the Elastic DRS algorithm is ignored. After the user-initiated operation completes, the algorithm may recommend a scale-in or scale-out operation based on the changes in the resource utilization and current selected policy.
If you start an add or remove host operation while an Elastic DRS recommendation is being applied, the add or remove host operation fails with an error indicating a concurrent update exception.
A planned maintenance operation means a particular host needs to be replaced by a new host. While a planned maintenance operation is in progress, current recommendations by the Elastic DRS algorithm are ignored. After the planned maintenance completes, the algorithm runs again and fresh recommendations are applied. If a planned maintenance event is initiated on a cluster while an Elastic DRS recommendation is being applied to that cluster, the planned maintenance task is queued. After the Elastic DRS recommendation task completes, the planned maintenance task starts.
During auto-remediation, a failed host is replaced by a new host, and its host tags are applied to the replacement host. While auto-remediation is in progress, the current recommendations by the Elastic DRS algorithm are ignored. After auto-remediation completes, the algorithm runs again and fresh recommendations are applied. If an auto-remediation event is initiated for a cluster while an Elastic DRS recommendation is being applied to that cluster, the auto-remediation task is queued. After the Elastic DRS recommendation task completes, the auto-remediation task starts.
If an SDDC is undergoing maintenance or is scheduled to undergo planned maintenance in the next 6 hours, EDRS recommendations are ignored.
Elastic DRS Policy
In a new SDDC, elastic DRS uses the Default Storage Scale-Out policy, adding hosts only when storage utilization exceeds the threshold of 75%. You can select a different policy if it provides better support for your workload VMs. For any policy, scale-out is triggered when a cluster reaches the high threshold for any resource. Scale-in is triggered only after all of the low thresholds have been reached.
Note: For two-host SDDCs, only the Default Storage Scale-Out policy is available.
The following policies are available:
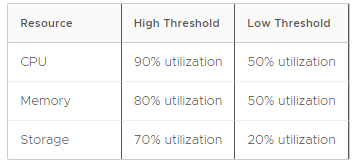
Optimize for Best Performance
This policy adds hosts more quickly and removes hosts more slowly in order to avoid performance slowdowns as demand spikes. It has the following thresholds:
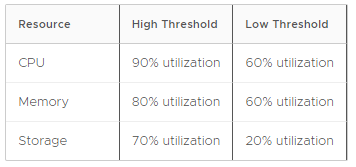
Optimize for Lowest Cost
This policy adds hosts more slowly and removes hosts more quickly in order to provide baseline performance while keeping host counts to a practical minimum. It has the following thresholds:
Optimize for Rapid Scale-Out
This policy adds multiple hosts at a time when needed for memory or CPU, and adds hosts incrementally when needed for storage. By default, hosts are added two at a time, but beginning with SDDC version 1.14 you can specify a larger increment if you need faster scaling for disaster recovery and similar use cases. When using this policy, scale-out time increases with the number of hosts added and, when the increment is large (12 hosts), can take up to 40 minutes in some configurations. You must manually remove these hosts when they are no longer needed. This policy has the following thresholds:

Elastic DRS policies are based on two variables:
Minimum cluster size
The minimum host count permits EDRS scaling. Once minimum cluster size is reached, EDRS cannot perform a scale-in operation, but you can still remove hosts manually until your organization’s minimum host count is reached.
Maximum cluster size
The maximum host count permits EDRS scaling. Once maximum cluster size is reached, EDRS cannot perform a scale-out operation, but you can still add hosts manually until your organization’s maximum host count is reached.