There are many new features have been introduced with vSphere 6.5 and In this post we are going to discuss about what’s new with HA in vSphere 6.5 .From vSphere 6.5 you can fin the configuration under vSphere Availability , you can check on below image .

Below are points we are going to discuss which are part of vSphere Availability .
- Admission Control
- Restart Priority enhancements
- HA Orchestrated Restart
- ProActive HA
Admission Control
Admission control has the same functionality as earlier with version 6.0 but with 6.5 , it is introduced in easier way with some more options . vSphere HA uses admission control to ensure that sufficient resources are reserved for virtual machine recovery when a host fails.

Navigate to Cluster -> Configure -> Services -> vSphere Availability and Edit on the option -> Select Admission Control

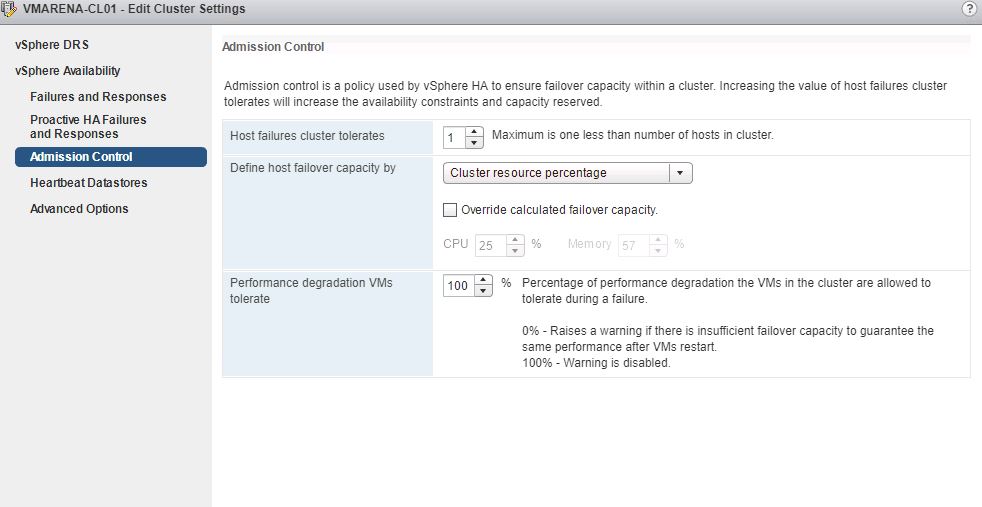
Cluster resource percentage
You can see the “Host failures cluster tolerates” as “1” which we selected on current configuration and “Cluster Resource Percentage” .If you scale up by adding new nodes or scale down by remove node , the percentage value will be automatically adjusted based on the selected number of failures you want to tolerate.As per our current configuration , we have four ESXi hosts in the cluster and we can run the VM infra with 1 host failure worth of 25% CPU and 57 % Memory
Another enhancement is “ Performance degradation VMs tolerate ” ,from this section you can specify the performance degradation you can accept for a failure. By default set to 100% , but you can configure for instance 25% or 50%, depending on your business requirement . This can be configured from the same option , just need to mention the percentage only and DRS should be enabled to use this feature .
Example
If you reduce the threshold to 0%, a warning is generated when cluster usage exceeds the available capacity.
If you reduce the threshold to 20%, the performance reduction that can be tolerated is calculated as performance reduction = current utilization * 20%. When the current usage minus the performance reduction exceeds the available capacity, a configuration notice is issued
Restart Priority Enhancements
This feature will allow you control the virtual machine startup priority if a host fails and HA triggered .We can set the priority in 3 modes high, medium or low .
Navigate to Cluster -> Configure -> Configuration -> VM Overrides and Click on Add

Select the virtual machines and click OK

Next Select the VMs by clicking the add option (green plus icon) and then specify their relative startup priority. Here I select on 2 VMs and then choose “lowest” option , also other available options are “low, medium, high and highest”.

After specifying the priority you can also specify other settings if required , example additional delay before the next batch will start , or you can specify even what triggers the next priority “group”, this could for instance be the VMware Tools guest heartbeat . Another option is “resources allocated” which is using for scheduling batch itself, the power-on event completion or the “app heartbeat” detection. app heartbeat option is completely depend on App HA , it has to enabled and services to be defined , it required detailed configuration .There are different value for heart beat detection and this can be modified ( decrease or increase ) as per requirement . If there is no Guest heartbeat , it will take more time to understand so there should be a timeout setting .

This Option is very useful in many cases such as if you have 2 VM ( Server and Application ) , first server should be powered on and then application .
HA Orchestrated Restart
HA Orchestrated Restart can be configured by creating “VM” Groups and assigning the VM Rule which is asscoaiated with the requirement .
Navigate to Cluster -> Configure -> Configuration -> VM/Host Groups and Click on Add to create new VM Group

Provide the Name for group the click on Add and select the First VM and click OK twice to close both windows .
Here we created Test Server Group and Add the Server VM to be part of Primary Group .

 Follow Same Create Another group for depended machine and here it is Test App .
Follow Same Create Another group for depended machine and here it is Test App .
After creation of both groups you can see both on the VM/Host Groups Option
Next Select the VM Groups according to requirement , here First is Server and then Application
Next Navigate to Cluster -> Configure -> Configuration -> VM/Host Rules and Click on Add provide the Policy Name
and add Type of Policy then VM Groups and Click OK .

Here we Choose the Rule Type Virtual Machine to Virtual Machine which will used for vSphere HA to restart virtual machines in the VM group Test Server first. When the cluster dependency restart condition has been met, virtual machines in the VM group Test App will be started afterwards.

There are Four Type which you can use for Set the Policy Rule , You have to choose the appropriate one .

Pro-Active HA
Proactive HA is a function of DRS not a vSphere HA , but it is part of “Availability” section in Configuration .Proactive HA will adds an additional layer of availability to your environment. Proactive HA integrates with the Server vendor’s monitoring software (more on this later), via a Web Client plugin, which will pass detailed server health status/alerts to DRS, and DRS will react based on the health state of the host’s hardware.
A Proactive HA failure occurs when a host component fails, which results in a loss of redundancy or a disastrous failure. However, the functional behavior of the VMs residing on the host is not yet affected .For example, if a power supply on the host fails, but other power supplies are available, that is a Proactive HA failure. If a Proactive HA failure occurs, the VMs on the affected host will be evacuated to other hosts and the host is either placed in Quarantine mode or Maintenance mode .

Navigate to Cluster -> Configure -> Configuration -> vSphere Availability Click Edit Option
Enable Proactive HA by selecting the Check box -> Turn on Proactive HA
Providers appear when their corresponding vSphere Web Client plugin has been installed and the providers monitor every host in the cluster. To view or edit the failure conditions supported by the provider, click the edit link.

Select Proactive HA Failures and Response Option as below and Click OK
Automation Level – Automated / Manual
Remediation gives you 3 options for how Proactive HA will handle host-degradation alerts.
- The first is to place a host into Quarantine Mode for any alert or degradation regardless of the severity.
- The second is to place hosts into Quarantine Mode for moderate degradation, but Maintenance Mode for severe degradation.
- The third option is to place hosts into Maintenance Mode for any alert or degradation regardless of severity.
Pro-Active HA will trigger for different types of failures like power supply, memory, network, storage and even a fan failure. Which state this results in (severe or moderate) is up to the vendor, this logic is built in to the Health Provider itself and w\this comes with the vendor Web Client plugins.

Health provider reads all the sensor data and analyze the results and then serve the state of the host up to vCenter Server. These states are “Healthy”, “Moderate Degradation”, “Severe Degradation” and “Unknown”. (Green, Yellow, Red) When vCenter is informed DRS can now take action based on the state of the hosts in a cluster, but also when placing new VMs it can take the state of a host in to consideration. The actions DRS can take by the way is placing the host in Maintenance Mode or Quarantine Mode.
Maintenance Mode – All VMs will be migrated off the host.
Quarantine Mode – This mode will attempt to evacuate it’s running virtual machines with below
- No impact of VM performance results on any virtual machine in the cluster
- None of the DRS Affinity/Anti-Affinity rules are violated
If the above are satisfied, then the VMs will evacuate and DRS will avoid placing virtual machines on said quarantined host.
{kind=link}